面向不平衡数据集的机器学习分类策略.pdf
”机器学习 不平衡数据 多分类“ 的搜索结果

在机器学习的众多挑战中,处理不平衡数据集是一个非常重要的问题。不平衡数据集意味着某些类的样本数量远多于其他类,这种情况在金融欺诈检测、医疗疾病诊断等领域尤为常见。本文将详细介绍如何通过合成少数过采样...
本数据集适合做不平衡多分类,从KEEL和UCI上下载后处理完,分成数据和标签,每个数据集都有独自名字,数据是.data格式也可以化成csvg格式。
数据预处理是机器学习项目中不可或缺的一环,它涉及到数据的清洗、格式化、归一化、特征提取等一系列操作,以便为后续的模型训练和分析提供高质量的数据集。同时,还需要注意数据的编码方式,确保数据在传输和存储...
在处理不平衡的数据集时,如果类不能与给定变量很好地分离,并且我们的目标是获得最佳的准确性,则最佳分类器可以是始终回答多数类的“幼稚”分类器
问题定义那么什么是不平衡数据呢?顾名思义即我们的数据集样本类别极不均衡,以二分类问题为例,假设我们的数据集是$S$,数据集中的多数类为$S_maj$,少数类为$S_min$,通常情况下把多数类样本的比例为$100:
总之,在机器学习建模过程中,需要注意数据质量、特征选择、模型选择、过拟合和欠拟合、不平衡数据、模型评估和模型部署等方面的问题,以提高机器学习建模的效果和应用价值。KNIME:KNIME是一种基于GUI界面的开源...
AI:机器学习算法分类
机器学习之不平衡数据集的处理方法1,不平衡数据集1.1 定义1.2 举例1.3 实例1.4 导致的问题2. 不平衡数据集常用的处理方法2.1 扩充数据集2.2 对数据集进行重采样 1,不平衡数据集 1.1 定义 不平衡数据集指的是数据集...

这类学习过程可以进一步分为「分类」(classification)任务和「回归」(regression)任务。在分类任务中,标签都是离散值; 而在回归任务中,标签都是连续值。线性回归是用于预测回归问题的算法。算法根据训练数据计算...
本次中我们将把注意力转向分类系统。我们曾经对MNIST进行了分类任务,这次我们重新回到这里,细致的再来一次。Scikit-Learn提供了许多助手功能来帮助你下载流行的数据集。MNIST也是其中之一。获取之: 结果是: 共有...
Python实战社群Java实战社群长按识别下方二维码,按需求添加扫码关注添加客服进Python社群▲扫码关注添加客服进Java社群▲作者丨琥珀里有波罗的海来源丨机器学习算法与Pyth...
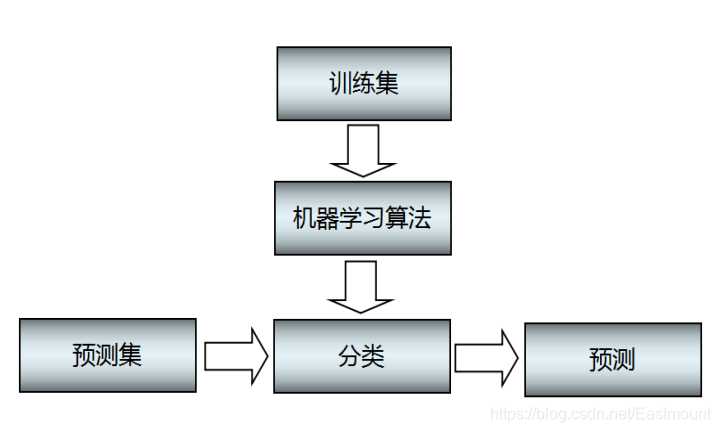
0 复习数据预处理及可视化1 了解分类的基本概念2 使用多种分类器来对比模型精度3 掌握使用分类器列表的方式来批处理不同模型4 将机器学习分类模型部署为Web应用分类是经典机器学习的基本重点,也是监督学习的一种...
0 复习数据预处理及可视化1 了解分类的基本概念2 使用多种分类器来对比模型精度3 掌握使用分类器列表的方式来批处理不同模型4 将机器学习分类模型部署为Web应用分类是经典机器学习的基本重点,也是监督学习的一种...


分类是经典机器学习的基本重点,也是监督学习的一种形式,与回归技术有很多共同之处。二元分类和多元分类。本文中,我将使用亚洲美食数据集贯穿本次学习。0线性回归可帮助我们预测变量之间的关系,并准确预测新数据...


不平衡数据集是指在解决分类问题时每个类别的样本量不均衡的数据集。 比如,在二分类中你有100个样本其中80个样本被标记为class 1, 其余20个被标记为class 2. 这个数据集就是一个不平衡数据集,class 1和class 2的...



数据不平衡是机器学习任务中的一个...在很多存在数据不平衡问题的任务中,我们往往更关注机器学习模型在少数类上的表现,一个典型的例子是制造业等领域的缺陷产品检测任务,在这个任务中,我们希望使用机器学习方...
推荐文章
- python入门(13)异常与文件_except filenotfounderror:-程序员宅基地
- Android面试攻略_详细了解在当今的社会里android工程师应具备什么的技能?并能详细说说自己的见解。-程序员宅基地
- Zendframework 1.6整合Smarty_setting private or protected class member is not a-程序员宅基地
- Qt-装饰者模式_qt装饰模式-程序员宅基地
- 新开普掌上校园服务管理平台service.action RCE漏洞复现 [附POC]-程序员宅基地
- 基于 Milvus 的音频检索系统-程序员宅基地
- 331、基于51单片机智能红外遥控暖风机温度无线蓝牙远程控制系统设计(程序+原理图+配套资料等)_红外感应暖风机自动控制系统设计-程序员宅基地
- Android自定义圆角矩形图片ImageView_android 矩形圆角imageview-程序员宅基地
- 又见回文 字符串-程序员宅基地
- switch的参数可以是什么类型?_switch的参数有哪些-程序员宅基地